
Rechnen in Assembler
 Für
viele ist das Rechnen in Assembler ein rotes Tuch. Die meisten
Programmierer einer Hochsprache schreiben einfach C=A*B in ihren Code
und lassen den Kompiler den Rest erledigen. Sie machen sich keine
Gedanken wie der AVR das intern erledigt. Warum sollten sie auch.
Gerade deshalb wurden ja Hochsprachen erfunden.
Für
viele ist das Rechnen in Assembler ein rotes Tuch. Die meisten
Programmierer einer Hochsprache schreiben einfach C=A*B in ihren Code
und lassen den Kompiler den Rest erledigen. Sie machen sich keine
Gedanken wie der AVR das intern erledigt. Warum sollten sie auch.
Gerade deshalb wurden ja Hochsprachen erfunden.
Jedoch, gerade in
Assembler kann man viele Vorteile nutzen, wenn man dem AVR etwas
entgegenkommt und die Zahlen die multipliziert oder dividiert
werden sollen genauer anschaut und überlegt auf welche Art
die
Berechnung durchgeführt werden soll. Deshalb möchte ich hier nicht nur
Grundroutinen zum multiplizieren und dividieren vorstellen, sondern
auch verschiedene
Rechenwege Aufzeigen. Hat man diese verstanden, weiß man sehr
genau, wann welche Rechenart
Vorteilhaft ist und wird letztendlich, durch einen schnellen und
kompakten Code belohnt.
Da es hier um Programmieren auf unterster Ebene geht,
rechnen wir hier nur mit Bits und Bytes. Das bedeutet aber nicht, dass
wir nur mit ganzen Zahlen rechnen können. Im Gegenteil. Wir bestimmen
selbst, wie viele Stellen nach dem Komma benötigt werden und belasten
unseren AVR nicht mit Berechnungen die 10 Stellen nach dem Komma
liefern und werfen dann 8 davon weg.
Meine Rechenbeispiele sind
alle mit AVR-Studio 4.19 programmiert. Möchte man die
Beispiele nachvollziehen, sollte man sich mit dem Debugger
(Simulator) im AVR-Studio vertraut machen.
Anmerkung: Die Codebeispiele beziehen sich auf meinen jetzigen
Wissensstand (05/2014). Ich programmiere jetzt zwar schon mehrere Jahre
Assembler auf den AVRs, aber gerade bei Berechnungen lerne ich ab und
an
immer noch etwas dazu. Verbesserungsvorschläge zu meinen Routinen per Email sind
also durchaus erwünscht.
Basics
Multiplizieren und dividieren durch wiederholtes addieren/subtrahieren
Bei dieser Technik wird in einer Schleife fortwährend der
Multiplikant zum Ergebnis addiert. Den Schleifenzähler bildet der
Multiplikator. Natürlich wird diese Technik kaum angewendet, da die
Laufzeit bei grösseren Zahlen ins unermessliche steigt und man kleine
Zahlen durch linksschieben effektiver multiplizieren kann.
Das dividieren funktioniert ähnlich. Hier wird in einer Schleife
gezählt,
wie oft der Dividend vom Divisor abgezogen werden kann, bis ein
Unterlauf auftritt. Das Ergebnis (der Quotient) ist dann der
Schleifenzähler -1.
Wenn man die Letzte Subtraktion Rückgängig macht erhält man im Dividend
den Rest. Diese Art der Division wird häufig bei der Wandlung einer
Zahl in einen String angewendet.
Anwendungsbeispiel:
;-------------------------------------------------------------------------------
;16Bitwert (max. 9999) in einzelne
(Dezimal) Ziffern
zerlegen
;-------------------------------------------------------------------------------
pos: ldi
temp1,-1
;1000er = -1
sub1000:inc
temp1
;1000er = +1
subi
temp2,low(1000)
;TSicwert-1000
sbci
temp3,high(1000)
brcc
sub1000
;Solange 1000 abziehen bis
Unterlauf
mov
chr4,temp1
;1000er wegspeichern
ldi
temp1,10
;100er = 10
add100: dec
temp1
;100er - 1
subi
temp2,low(-100) ;TSicwert +100
sbci
temp3,high(-100)
brcs
add100
;Solange +100 bis
Überlauf
mov
chr3,temp1
;Zehner
ldi
temp1,-1
sub10: inc
temp1
subi
temp2,10
;-10
brcc sub10
subi
temp2,-10
mov
chr2,temp1
;Einer
mov
chr1,
temp2
;Rest = 10tel
Will man eine Zahl auf einem Display Dezimal ausgeben, muss
man
diese in einzelne Ziffern zerlegen. Dies geschieht im Codebeispiel
oben. Die einzelnen Ziffern werden zwecks späterer Ausgabe auf einer
Siebensegmentanzeige benötigt und deshalb in den Registern chr1..4
Zwischengespeichert. Die Zahl liegt in den Registern temp2 /
temp3 (low/high) als 16-Bit Wert vor und übersteigt 9999
nicht, sodass
sichergestellt ist, das 4 Stellen genügen um diese darzustellen. Um die
erste Ziffer (die 1000er Stelle) zu erhalten, muss temp2/temp3
durch 1000dez dividiert werden. Der Rest wird aufbewahrt um
daraus
später die 100er, 10er und 1er zu berechnen. Da der Schleifenzähler
temp1
mit -1 initialisiert wird, hinkt dieser der Division um 1
hinterher damit beim Ende der Schleife (beim Unterlauf) keine 1 mehr
abgezogen werden muss.
Nun sind ja durch den Unterlauf 1000 zuviel abgezogen worden und
dadurch temp2/temp3
ins negative gerutscht. Normalerweise würde man
durch aufaddieren von 1000 die letzte Subtraktion Rückgängig machen. Im
Code oben spare ich mir die (16-Bit) Addition und addiere bei der 100er
Stelle 100 bis zum Überlauf. Zu beachten ist, das der Zähler mit 10
initialisiert wird und in der Schleife heruntergezählt wird. Da wir
jetzt wieder im positiven Bereich sind, wird bei den 10ern wieder
abgezogen. Die 1er Stelle ist der Rest der Division durch 10, deshalb
wird in diesem Fall, die letzte Subtraktion durch aufaddieren von 10
(subi
temp2,-10) wieder Rückgängig gemacht. Bei den 10ern rechne
ich,
wie man sieht, nur noch mit 8-Bit.
Die einzelnen Ziffern in chr1..4,
können nun als Index auf eine
Tabelle mit Siebensegmentcodes verwendet werden. Bei der Ausgabe auf
ein LCD muss einfach noch zu jedem Wert der Offset des LCD-Zeichen '0'
addiert werden, bevor man es zum Display schickt.
Multiplizieren durch Linksschieben.
Soll eine Konstante mit einem Register Multipliziert werden, ist linksschieben die einfachste Art dies durchzuführen.
Beispiel: In Register R16 befindet sich die Zahl 1. Nach ausführen des Befehl lsl r16, wird von rechts eine 0 eingeschoben und r16 enthält als Ergebnis eine 2. Das Register wurde mit 2 multipliziert. Jeder weitere lsl r16 Befehl verdoppelt die Konstante: Anders gesagt, der Exponent der 2er Potenz wird um 1 erhöht. Wird also 3 mal Links geschoben wurde mit 8 multipliziert (2^3 =8). Das Funktioniert auch mit 16-Bit (oder noch höheren) Zahlen indem der Überlauf über das Carry-Flag, ins nächste Register geschoben wird. Es sind dann 2 Befehle Notwendig, nämlich lsr r16 mit nachfolgendem rol r17. Beschränkt man sich auf die Schiebebefehle, können so nur 2er Potenzen multipliziert werden. Der Trick, X-Beliebige Zahlen als Multiplikant zu benutzen, besteht darin, das man sich Zwischenergebnisse merkt und diese an geeigneter Stelle addiert oder subtrahiert. Soll z.B r16 mit 14 multipliziert werden gibt es mehrere Möglichkeiten.
Anfangswert merken, 3 mal schieben(*8), Anfangswert abziehen(*7), 1 mal schieben(*14). ODER. 1 mal schieben (*2), merken, 3 mal schieben (*16), abziehen (*14).
So wird klar, das der Code in Größe und Laufzeit von der verwendeten Zahl des Multiplikanten abhängt.
Bytes anfügen
Auch grössere Zahlen können durch schieben multipliziert
werden. Ein
Anfügen einens Nullbytes entspricht 8* nach links schieben.
Ähnlich wie im Dezimalsystem das Komma bei einer Multiplikation mit
10 um eine Stelle nach rechts verschoben wird, kann im Binärsystem eine
Multiplikation mit 256 (0x100) einfach erfolgen, indem man einfach ein
Nullbyte anhängt. Soll also z.B. ein Byte mit 128 multipliziert werden,
hängt man
zuerst ein Nullbyte an und schiebt dann das 16-Bit Paket einmal nach
rechts welches den 256fachen Wert durch 2 dividiert.
Beispiel:
In r20/r21 befindet sich der Wert 10 als 16 Bit Wert (0x000A). Dieser soll mit 256 (0x100) multipliziert werden. Dieses kann man erreichen indem man r20/r21 8 mal nach links schiebt. Die Befehle dazu währen 8 mal hintereinander lsl r20 gefolgt von rol r21. Als Ergebniss hätten wir wieder 10 (0x0a) im Highbyte (r21) und 0 im Lowbyte (r21) was dem Dezimalen Ergebniss von 2560 (0x0A00) entspricht. Die ganze Schieberei kann man also Abkürzen in dem man im Beispiel oben r20 nach r21 kopiert und r20 löscht (auf 0 setzt). Noch kürzer, wird das ganze, wenn einfach r19 gelöscht wird und r20 als Highbyte und r19 als Lowbyte angesehen wird. Das anfügen von Bytes kann, wie im Dezimalsystem das rechtsschieben des Kommas *10 bewirkt, fortgeführt werden. Das anfügen von r18 hätte also eine weitere Multiplikation mit 256 zur Folge, wenn r20..r18 als 24-Bit Zahl angesehen würde. Das Funktioniert natürlich auch rückwärts. Das entfernen des niederwertigsten Bytes kommt einer Division mit 256 gleich.
Manchmal ist es auch notwendig die ursprünglichen Werte zu erhalten und
ein oder mehrere Ergebnisregister zu definieren. Bei einer
Multiplikation von der Konstante 256 ist das besonders einfach. Wenn
der Wert R20*256 in r22 und r23 gespeichert werden soll,
braucht
nur r22 gelöscht zu werden (clr r22) und r20 nach r23 (mov r23,r20)
kopiert zu werden.
Es lohnt sich bei einer Multiplikation also immer, nachzuprüfen ob
diese mit Schiebebefehlen und/oder hinzufügen von Nullbytes Zeit und
Codesparend durgeführt werden kann. Das kann unter Umständen schneller
und kürzer sein als, als wenn man die Rechnung mit dem
Hardwaremultiplizierer durchführen lässt.
Beispiel: Multiplikation mit 250
;
Temperatur*10=(TSic_Wert*250)/256-500
;---------------------------------------------------------------------------------------
clr
temp1
;temp3/2/1 enthält durch zufügen von
Temp1 (0)
mov
temp2,rawlow ;den TSicwert *
256
mov
temp3,rawhigh
lsl
rawlow
;*2
rol
rawhigh
add
rawlow,temp2 ;*3
adc
rawhigh,temp3
lsl
rawlow
;*6
rol
rawhigh
sub
temp1,rawlow ;*256 - *6 =
*250
sbc
temp2,rawhigh ;TSic_Wert*250 steht
jetzt in temp1/temp2/temp3
sbci
temp3,0
;Durch verwerfen von temp1
wird durch 256
geteilt
subi
temp2,low(500) ;
500 (50.0) abziehen
sbci
temp3,high(500)
;Nun steht die Temperatur(*10) in temp2 (low) und temp3 (high)
Im Code oben soll der Rohwert eines TSIC206 Temperetursensors
in C° umgerechnet werden. Die
Ausleseroutine liefert den 16-Bit Rohwert in rawlow/rawhigh. Der Wert
hat eine Range von 0..0x7ff und soll zunächst mit 250dez multipliziert
werden. Dazu wird der Wert in die 3 Ergebnissregister temp1..3 kopiert
und gleich um 8 Bit nach links verschoben, was einer Multiplikation von
256 gleichkommt. Die nächsten 6 Befehle, multiplizieren den Rohwert
durch schieben und addieren mit 6. Nach dem subtrahieren vom 24-Bitwert
(*256) , ist das Produkt der Multiplikation (rawlow/rawhigh*250) in den
Registern Temp1..3 gespeichert.
Durch verwerfen (wegdenken) von temp1 wird durch 256 geteilt. Die
Subtraktion von 500 laut Formel ist trivial und muss hier nicht weiter
erklärt werden.
Mit dem Codeschnippsel oben, wollte ich zeigen das durch Bitschieben
durchaus effizient multipliziert werden kann wenn die Zahlen passen.
Herauszufinden ob die Zahlen passen, ist die Aufgabe des
Programmierers. Übrigens könnte oben noch 1 Befehl eingespart werden,
wenn man die 2 mov Befehle durch einen movw Befehl zusammenfassen würde.
Multiplizieren mit einer Tabelle (LUT)
Das Multiplizieren mit einer Tabelle (Spickzettelmethode  ) muss eigentlich nichts
rechnen, sondern sie muss nur wissen wo das Ergebniss steht.
Multiplizieren mit einer LUT
kann durchaus sinvoll sein. Dies trifft 1. zu, wenn der Bereich des
Multiplikanten klein ist, oder 2. eine besonders schnelle
Laufzeit erwünscht ist. In der Tabelle könnten natürlich auch
Festkommawerte eingetragen werden. Im Beispiel unten wird 700
mit
8 multipliziert.
) muss eigentlich nichts
rechnen, sondern sie muss nur wissen wo das Ergebniss steht.
Multiplizieren mit einer LUT
kann durchaus sinvoll sein. Dies trifft 1. zu, wenn der Bereich des
Multiplikanten klein ist, oder 2. eine besonders schnelle
Laufzeit erwünscht ist. In der Tabelle könnten natürlich auch
Festkommawerte eingetragen werden. Im Beispiel unten wird 700
mit
8 multipliziert. .def
temp1 = r16
.def null
= r2
clr null
ldi
temp1,8
;Testwert, in diesem Fall 8*700
;------------------------------------------------------------------------------
lsl
temp1
;Tabellenzeiger*2, da Words in der Tab stehen
ldi
zl,low(mul700<<1) ;Zeiger auf ersten
Tabelleneintrag
ldi
zh,high(mul700<<1)
add
zl,temp1
;Offset addieren (in diesem Fall 16 Bytes überspringen)
adc
zh,null
;Carry addieren.
lpm
yh,z+
;16 Bit Wert (5600) aus der Tabelle nach Y holen
lpm yl,z
;-------------------------------------------------------------------------------
stop: rjmp stop
;Mit dieser kleinen Tab. kann die Ziffer 0..13 (8 Bit in
temp1) mit 700 multipliziert werden
mul700: .dw
0,700,1400,2100,2800,3500,4200,4900,5600,6300,7000,7700,8400,9100
Natürlich muss die die Tabelle den höchsten Wert die der
Multiplikant annehmen kann abdecken. Die Vorteile der LUT
ist die enorme Geschwindigkeit die unabhangig vom Wert des
Multiplikators immer gleich bleibt. Die Nachteile sind bei grösseren
Tabellen der Flashspeicherverbrauch.
Mit Tabellen können alle möglichen Rechenoperationen durchgeführt
werden. Das Beispiel oben zeigt nur eine einfache Variante. Es könnten
zum Beispiel anstatt des 16-Bitwert auch gleich der Siebensegmentcode
oder ASCII-Zeichen für ein LCD in die Tabelle eingetragen werden.
Multiplizieren in Hardware
Im Gegensatz zu den Tiny AVRs ist in den ATMegas der mul Befehl enthalten, der 2 Bytes miteinander multipliziert und das 16 Bit Ergebniss in den beiden Registern R0 und R1 liefert. In der Appnote 201 von Atmel, kann man nachlesen, wie man mit mehreren 8-Bit Multiplikationen und anschließendem addieren, 2 16-Bit Zahlen miteinander Multipliziert. Besser ist es jedoch, wenn man sich etwas mit der Materie beschäftigt und selbst weiß, wie die einzelnen mit mul multiplizierten Bytes zu den Ergebnissregistern addiert werden um so z.B 24 * 8 Bit Multiplikationen oder beliebig andere Kombinationen ausführen zu lassen.
Beispiel:
Die Register r16, r17,r18 sollen mit r19 multipliziert werden. Das ist eine 24*8 Bit Multiplikation und benötigt daher 4 Register um das 32-Bit Ergebnis zu speichern. Wir nehmen hier einfach r20..r23. Wie man schon vermuten kann benötigt man 3 8-Bit Multiplikationen um die Rechnung durchzuführen. Die einzelnen Teilmultiplikationen werden alle mehr oder weniger verschoben dem Ergebnis hinzugefügt (addiert, gemovt). Zunächst wird das niederwertigste Byte r16, durch mul r16,r19 multipliziert. Das Ergebnis, welches sich schon nach 2 Taktzyklen in r0 und r1 befindet, wird in die Ergebnisregister r20 und r21 kopiert.
;Multiplikation
24*8 Bit by
Juergen@avr-projekte.de
.equ f1 =$abcdef
.equ f2 =$f8
.org 0
clr
r2
ldi
r16,byte1(f1)
;Testwerte laden
ldi
r17,byte2(f1)
ldi
r18,byte3(f1)
ldi
r19,f2
;---------------------------------------
;Multiplikation r20..r23 =
r16..r18 * r19
;---------------------------------------
mul24_8:clr r22
clr
r23
mul
r16,r19
;byte1 * r19
movw
r20:r21,r0:r1
;Ohne verschieben ins
Ergebniss
mul
r17,r19
;byte2 * r19
add
r21,r0
;Um 1 Byte verschoben addieren (* 0x100)
adc
r22,r1
adc
r23,null
mul
r18,r19
;byte3 * r19
add
r22,r0
;Um 2 Byte verschoben addieren (*0x100 * 0x100)
adc
r23,r1
brk: rjmp
brk
Da r17 an 2. Stelle im 24Bit Wert steht, müssen wir hier in
Gedanken
ein Nullbyte anhängen . Das Nullbyte denken wir uns
als an R17 angehängt und multiplizieren das Highbyte (r17) von unserem
gedachten
16-Bit Wert mit r19.
An das Ergebnis in R0 und R1 kommt also
noch ein weiteres gedachtes Register Rx welches Null (eine Zahl mal 0
ist immer null) enthält und somit
das Niederwertigste Byte im 24 Bit Ergebnis r1,r0 und rx darstellt.
Diese 3 Register werden nun zum Ergebniss addiert.
Die Erklärung oben, mit den gedachten Registern läuft im Endeffekt
darauf hinaus, dass wir das Ergebnis in r0 und r1 um um eine Stelle (1
Byte/8 Bit) nach links zum Ergebnis addieren, wenn r17 eine Stelle im
Multiplikant nach links verschoben ist. Diese Verschiebung
bewirkt, das das Ergebnis nochmals mit 256dez (0x100) multipliziert
wird.
Bei r18 * r19 müssen 2
Nullbytes angehängt werden und das Ergebnis in r0 und r1, sind dann
eben Byte3 und Byte4 des 32 Bit Ergebnis. Wir verschieben die Addition
also um 2 Bytes, wenn im Multiplikant rechts noch 2 Bytes vorhanden
sind.
Im Code oben, werden die einzelnen Bytemultiplikationen der
Reihe
nach durchgeführt. Damit Zwischenergebnisse später hinzuaddiert werden
können, wird am Anfang r22 und r23 gelöscht. Da die Reihenfolge der
Teilmultiplikationen keine Rolle spielt, kann man durch eine geschickte
Festlegung dieser
Reihenfolge noch etwas Code sparen. Im Code unten
wurde diese so verändert, das nur noch eine Multiplikation
addiert werden muss und die clr Befehle wegfallen können. Das lässt den
eh schon kleinen Code der Multiplikation, von 11 auf 8 Befehle
schrumpfen.
;Multiplikation
24*8 Bit by
Juergen@avr-projekte.de
.equ f1 =$abcdef
.equ f2 =$f8
.org 0
clr
r2
;Wird zum Carry addieren benutzt
ldi
r16,byte1(f1)
;Testwerte laden
ldi
r17,byte2(f1)
ldi
r18,byte3(f1)
ldi
r19,f2
;---------------------------------------
;Multiplikation r20..r23 =
r16..r18 * r19
;---------------------------------------
mul24_8:mul
r16,r19
;byte1 * r19
movw
r20:r21,r0:r1
;Ohne verschieben ins
Ergebniss
mul
r18,r19
;byte3 * r19
movw
r22:r23,r0:r1
;Um 2 Byte verschoben
ins Ergebniss (*0x10000)
mul
r17,r19
;byte2 * r19
add
r21,r0
;Um 1 Byte verschoben addieren (* 0x100)
adc
r22,r1
adc
r23,null
brk: rjmp
brk
In der folgenden Tabelle wird als Beispiel eine 24Bit Zahl
mit
einer 16 Bit Zahl Multipliziert. Das 40 Bit-Ergebnis wird den Registern
E1 bis E5 hinzugefügt (gemovt oder addiert). Da links vom Malzeichen
der Multiplikation 3 Bytes und rechts davon 2 Bytes stehen sind
insgesamt (3*2) 6 einzelne 8-Bit Multiplikationen notwendig. Da 5
Register für die Faktoren gebraucht werden, sind auch 5 Register für
das Ergebnis notwendig.
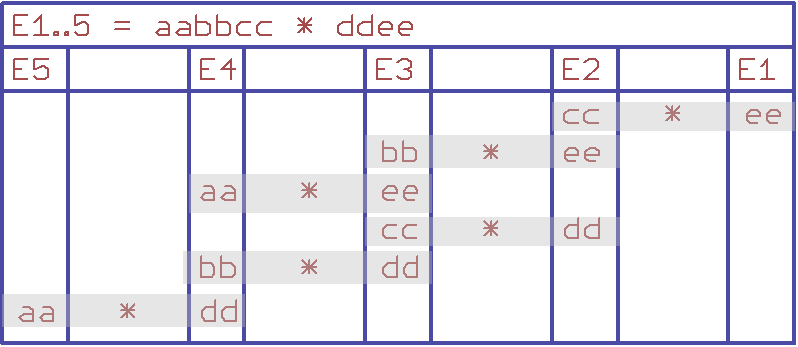
Unabhängig von der Bitbreite der Faktoren kann man also
sagen:
- Es müssen alle Bytes rechts und links von der Multiplikation (dem Multiplikationszeichen) miteinander Multipliziert werden.
- Man zählt bei beiden zu multiplizierenden Bytes wie viele
Stellen
(Bytes) nach
rechts vorhanden sind. Bei der Addition zum Ergebnis schiebt man das
Zwischenergebnis um die gezählte Anzahl nach links.
- Man benötigt so viele Bytes für das Ergebnis, wie man für
die
Faktoren benötigt. Es sei denn, die Range (z.B. 10 Bit beim AD-Wandler)
ist bekannt.
- Die
Reihenfolge der Teilmultiplikation spielt keine Rolle. Die geschickte
Festlegung der Reihenfolge, kann man clr und add Befehle einsparen.
Abschießend zur Hardwaremultiplikation möchte ich noch die
Befehle
muls und mulsu erwähnen, welche mit einer oder zwei negativen Zahlen
multiplizieren. Ich hatte bisher noch keine Verwendung für diese
Befehle, da ich bisher die Formeln immer so drehen konnte, dass ich im
positiven Bereich rechnen konnte.
Multiplikation
in Software
Haben wir einen Tiny AVR am Start, können wir den mul Befehl
leider
nicht nutzen, da dieser nur bei den Megas verfügbar ist. Hier bietet
sich an, den mul Befehl in Software nachzubilden um diesen als
Unterprogramm oder Makro nachzubilden. Im Beispiel unten ist erst
einmal ein Codeschnipsel der r16 mit r17 multipliziert. Das Ergebnis
(Produkt) ist wie beim mul Befehl im Registerpaar r0/r1. Der
Algorithmus erinnert stark an das multiplizieren wie es in der
Grundschule im Dezimalsystem gelehrt wird. Es ist eigentlich im
Binärsystem noch einfacher, da nur mit 0 und 1 multipliziert wird.
;Multiplikation
8*8 Bit by
Juergen@avr-projekte.de
;
r16=137 * r17=12
;
-------------------
;
10001001 * 00001100 LSB(r16)
;
------------------- ___
;
------->00001100 |1| (8
mal rechts schieben)
;
00000000 |0| (7)
;
00000000
|0| (6)
;
00001100
|1| (5)
;
00000000
|0| (4)
;
00000000
|0| (3)
;
00000000
|0| (2)
;
00001100
|1| (1 mal rechts schieben)
;
---------------- ---
;
0000011001101100 MSB(r16)
;
|--R1--||--R0--|
;
1644dez
#include "tn2313def.inc"
ldi
r16,200 ;Testwerte laden
ldi
r17,150
;----------------------------------
;Multiplikation r0..r1 = r16
* r17
;----------------------------------
_mul: clr
r1 ;Ergebnis = 0
ldi
xl,8 ;8 mal schieben
mul1: lsr
r16 ;Bit (von 0..7
Niederwertige zuerst) ins
Carry (Multiplikand)
brcc
mul2 ;Wenn 0, Addition überspringen
add
r1,r17 ;Ansonsten Multiplikator ins Highbyte addieren
mul2: ror
r1 ;Produkt mit evt.
Übertrag nach rechts
schieben
ror
r0
dec
xl ;Das ganze 8 mal
brne mul1
;----------------------------------
;Ende mul
;----------------------------------
brk: rjmp
brk
Viele dieser Routinen schieben das MSB
zuerst ins
Carry und schieben dann das Ergebnis der Addition in einer Schleife
nach links. Beispiel http://www.mikrocontroller.net/articles/AVR-Tutorial:_Arithmetik8#Multiplikation_in_Software.
Die Routine oben, nimmt den Umgekehrten Weg. Zuerst wird das LSB
durch
rechtsschieben ins Carry geholt. Ist dieses gesetzt, wird der
Multiplikator zum Highbyte
des Ergebnis (r1) addiert und anschließend nach rechts geschoben. Im
weiteren Verlauf der Schleife, die ja 8 mal durchlaufen wird, wandert
das Ergebniss immer weiter nach rechts (in r0) und befindet sich am
Ende an der
richtigen Position.
Bei jedem weiteren Durchlauf, wird das nächsthöhere Bit ins Carry
geschoben, welches wieder bestimmt, ob addiert werden muß (1), oder
nicht (0).
Vergleicht man den Code mit dem herkömmlichen Algorithmus, wird man
feststellen, das ein paar Befehle eingespart werden können. Es braucht
nur noch ein clr für das Highbyte. Der adc Befehl der normalerweise dem
add folgt, kann auch entfallen. Dies ist besonders angenehm, da sich
dieser in der Schleife befindet und somit auch ein bisschen Laufzeit
spart.
Will man den Code oben als Ersatz für den mul Befehl 1:1 als
Makro
ausführen, hat dieser 2 Schönheitsfehler. 1) Es wird beim Aufruf r16
zerstört. Dieses muss, um mit dem mul Befehl Kompatibel zu sein gepusht
werden. 2) Es wird ein Schleifenzähler benutzt. Dieses Register kann
also nicht als Multiplikant herhalten. Diesen könnte man zwar
auch pushen und umkopieren, doch es gibt noch eine andere Möglichkeit
die auch ohne
einen Schleifenzähler auskommt.
;Multiplikation
8*8 Bit by
Juergen@avr-projekte.de
#include "tn2313def.inc"
.macro _mul
;---------------------------------
;mul Befehl in Software als
Makro
;---------------------------------
clr
r1 ;Ergebnis = 0
push
@0 ;Multiplikant
wegspeichern
sec
;Multiplikant ersetzt gleichzeitig den Schleifenzähler
ror
@0 ;Eine 1 rein, LSB
raus
rjmp
mul2 ;Beim 1. Durchgang, gleich LSB
auswerten
mul1: lsr
@0 ;Bit (von 1..7
Niederwertige zuerst)
ins Carry (Multiplikand)
breq
mul4 ;Wenn die 1 von sec (oben) wieder im
Carry ist,
Ende
mul2: brcc
mul3 ;Wenn
0, Addition überspringen
add
r1,@1 ;Ansonsten Multiplikator ins Highbyte addieren
mul3: ror
r1 ;Produkt mit evt.
Übertrag nach rechts
schieben
ror
r0
rjmp mul1
;Noch ne Runde (von insgesamt 8)
mul4: pop
@0 ;Multiplikant
zurückholen
.endm
;---------------------------------
;Ende Makros
;---------------------------------
ldi
r16,250 ;Testwerte laden
ldi
r17,150
_mul
r16,r17 ;Makroaufruf
brk: rjmp
brk
Dazu wird vor der Schleife eine 1 in den Multiplikator
geschoben.
Die 1 wandert in der Schleife dann (lsr Befehl) durch das komplette
Register. Ist die 1 dann wieder im Carry angelangt, wurden durch den
lsr Befehl 8 Nullen eingeschoben, die Zeile < breq mul4 >
greift
und springt aus der Schleife.
Das Makro ist in der Laufzeit zwar etwas länger als die Version weiter
oben, dafür aber (fast) Kompatibel mit dem mul Befehl, da es ohne
zusätzliche Register auskommt. Das fast
bedeutet, dass r0 und r1 nicht
miteinander multipliziert werden dürfen, beim Hardwaremultiplizierer
ist das möglich. Wer auch das möchte, muss den Code durch weitere
push/pop Befehle erweitern. Das Makro ist geeignet, wenn ein Programm,
das von einem ATMega stammt auf einen Tiny angepasst werden soll bei
dem der mul Befehl häufig zum Einsatz kommt. Kürzer und auch schneller
ist es allerdings, wenn man gleich Routinen benutzt die in der
Bitbreite zur jeweiligen Aufgabe passen. Unten habe ich zwei Beispiele
für 16*16 Bit Multiplikationen. Die erste schiebt vom LSB nach links,
die zweite schiebt (wie oben erklärt) nach rechts. Hat man den
Algorithmus erst einmal verstanden, ist es ein leichtes die Routinen
auf andere Bitbreiten anzupassen.
Nach links
;-------------------------------------------------------------------------
;Multiplikation 16*16=32 Bit. Faktor1=Y, Faktor2=Z, Ergebniss
temp1..temp4
;-------------------------------------------------------------------------
mul16: ldi
temp5,16
;16*schieben
clr
temp1
;Ergebnis (Produkt)löschen
clr
temp2
clr
temp3
clr
temp4
mul01: lsl
temp1
;Ergebniss
schieben
rol
temp2
rol
temp3
rol
temp4
lsl
yl
;Herausgeschobenes Bit aus
Multiplikator (ADC)..
rol
yh
;..entscheidet ob addiert wird
brcc
mul02
;Wenn
Bit=0 nicht addieren
add
temp1,zl
;Wenn
Bit=1 Multiplikant (Formel) zum Ergebniss addieren
adc
temp2,zh
adc
temp3,null
adc
temp4,null
mul02: dec
temp5
;Alle 16
Bit durch ?
brne mul01
ret
Nach rechts
;Multiplikation
16*16 Bit by
Juergen@avr-projekte.de
#include "tn2313def.inc"
.equ zahl1
= 40000
.equ zahl2
= 50000
ldi
r16,low(zahl1) ;Testwerte laden
ldi
r17,high(zahl1)
ldi
r18,low(zahl2) ;Testwerte laden
ldi
r19,high(zahl2)
;------------------------------------------
;Multiplikation r0..r3 =
r16:r17 * r18:r19
;
(low...high)(low/high)(low/high)
;------------------------------------------
_mul: clr
r3 ;Ergebnis = 0
clr
r2
ldi
xl,16
mul1: lsr
r17 ;Bit (Niederwertige zuerst)
ins Carry
(Multiplikand)
ror
r16
brcc
mul2 ;Wenn 0, Addition überspringen
add
r2,r18 ;Ansonsten Multiplikator ins Highbyte addieren
adc
r3,r19
mul2: ror
r3 ;Produkt mit evt.
Übertrag nach rechts
schieben
ror
r2
ror
r1
ror
r0
dec
xl ;Das ganze 8 mal
brne mul1
;----------------------------------
;Ende mul
;----------------------------------
brk: rjmp
brk
Dividieren
Dividieren durch rechtsschieben
Das Dividieren durch rechtsschieben funktioniert nur bei
Zweierpotenzen. Hier kann man leider nicht, wie beim Multiplizieren
Zwischenwerte addieren oder subtrahieren. Zweierpotenzen kommen aber
gerade im Assemblercode recht häufig
vor. Beim anlegen eines mehrdimensionalen Array (LUT,
Tabelle) ist es oft von Vorteil, wenn die Anzahl der Einträge eines
Datenblocks auf z.B. 2,4 oder 8 anlegt, da so der Zeiger (Z-Register)
einen schnellen Zugriff ermöglicht. Der Programmierer, der einen
schnellen und unkomplizierten Zugriff wünscht, provoziert hier geradezu
eine Zweierpotenz und opfert bei kleineren Tabellen lieber
ein Füllbyte in der Tabelle, als
das er er mit 7 multipliziert oder dividiert.
Rest
Oft wird der Rest benötigt. Der kann bei einer Division die durch schieben erfolgt, vor der eigentlichen Division berechnet werden. Beispiel: Ein Byte in r16 sol durch 8 geteilt werden, der Rest wird in r17 gespeichert.
#include
"m48def.inc"
.equ
dividend = 100
ldi
r16,dividend ;Dividend
mov
r17,r16
;Rest nach r17
andi
r17,0b111
;Rest ausmaskieren
lsr
r16
;r16 /2
lsr
r16
;/4
lsr
r16
;/8
Da man bei einer Division durch 8 weiß, das 3 mal geschoben
wird,
werden einfach die unteren 3 Bits ausmaskiert. Also: Die Bits, die
später herausgeschoben werden, müssen beim ausmaskieren stehen bleiben.
Runden
Das Auf- und Abrunden einer Division, kann erfolgen indem man
einfach den halben Divisor zum Dividenden addiert. Um beim Beispiel von
oben zu bleiben, wird im Code unten zum Dividend der durch 8 geteilt
werden soll, 4 addiert.
#include
"m48def.inc"
.equ
dividend = 100
ldi
r16,dividend ;Dividend
add
r16,4
;Den
halben Dividend (8/2) addieren
lsr
r16
;r16 /2
lsr
r16
;/4
lsr
r16
;/8
Das Runden durch Addition des halben Divisors funktioniert bei
allen Arten der Division genauso.
Division
vermeiden
Man kann eigentlich jede Division vermeiden, indem man mit dem Kehrwert multipliziert. Dazu muss der Divisor allerdings bekannt sein.
Beispiel:
Ein Byte soll durch (die dem ASM-Programmierer unsympathische  ) 7 dividiert werden. Wir benutzen
den
Taschenrechner und rechnen 1/7. Das Ergebnis ist 0,1428571428571429.
Eine Multiplikation mit dieser Zahl teilt unser Byte also durch 7.
Leider passt die Zahl kein AVR-Register, wir müssen also noch etwas
daran drehen. Zuerst multiplizieren wir 0,1428571428571429 mit 256 und
sehen uns das Ergebnis von 36,57142857142857 an. Wir könnten
nun
auf oder abrunden und unser Byte mit 36 oder 37 multiplizieren und das
Ergebnis wieder durch 256 Teilen. Die Division durch 256 ist für den
AVR ein Klacks. Es wird einfach 8 mal nach rechts geschoben oder wie
schon oben beschrieben das Lowbyte verworfen (wir denken uns das ganz
einfach weg). Damit kommen wir dem richtigen Ergebnis schon recht nahe.
) 7 dividiert werden. Wir benutzen
den
Taschenrechner und rechnen 1/7. Das Ergebnis ist 0,1428571428571429.
Eine Multiplikation mit dieser Zahl teilt unser Byte also durch 7.
Leider passt die Zahl kein AVR-Register, wir müssen also noch etwas
daran drehen. Zuerst multiplizieren wir 0,1428571428571429 mit 256 und
sehen uns das Ergebnis von 36,57142857142857 an. Wir könnten
nun
auf oder abrunden und unser Byte mit 36 oder 37 multiplizieren und das
Ergebnis wieder durch 256 Teilen. Die Division durch 256 ist für den
AVR ein Klacks. Es wird einfach 8 mal nach rechts geschoben oder wie
schon oben beschrieben das Lowbyte verworfen (wir denken uns das ganz
einfach weg). Damit kommen wir dem richtigen Ergebnis schon recht nahe.
Die Zahl hinter dem Komma ist ausschlaggebend. 36,57142857142857 ist
recht ungünstig, da eine 5 hinter dem Komma steht. Gut ist eine 1
Optimal währe eine Null. Wir multiplizieren die 36,57142857142857
nochmals mit 2 und erhalten 73,14285714285714. Besser. Nun wissen wir
das wir abrunden können und unser Byte wird mit 73 multipliziert. Das
Ergebnis wird einmal nach rechts geschoben (durch 2 geteilt) und wieder
das Lowbyte verworfen.
Das Programm dazu ist einfach.
.equ
dividend = 100
ldi
r16,73
;Kehrwert
von 7 *256 *2
ldi r17,dividend
mul
r16,r17
;Multiplizieren
lsr
r1
;Durch 2 teilen und r0 verwerfen
Der Quotient von r17 durch 7 ist nun in r1. Natürlich muss das
im
Simulator mit mehreren Dividenden geprüft und nachgerechnet werden.
Gute Dienste leiste hier der Windows Rechner, der im
Programmierer-Modus auch mit Hex und Binärzahlen umgehen kann. Ist das
Ergebnis noch nicht zufriedenstellend, wird ein weiteres Byte angehängt
und mit 65536 (0x10000) multipliziert und wieder evtl. geschoben. Es
werden dann eben die unteren 2 Bytes verworfen. So kann man für fast
jeden Dividenden einen passenden Multiplikanden finden. Man muss nur
aufpassen, das man das, was man vorher mit der Zahl am Taschenrechner
anstellt, später im Code wieder rückgängig macht. Das ganze auf
grössere Zahlen zu übertragen ist einfach. Das multiplizieren von
grösseren Zahlen ist ja oben schon erklärt.
Das
Ergebnis oben ist abgerundet. Möchte
man gerundete Ergebnisse erhalten, addiert man auch
hier einfach vor
der Division den halben Divisor (einmal rechts schieben) in
diesen Fall 3 zum Dividenden.
Komplizierter als beim schieben, wird es wenn der Rest benötigt wird.
Hier muss der
Quotient mit dem Divisor multipliziert werden und vom Dividend
subtrahiert.
Der Code dazu:
#include "m48def.inc"
.equ
dividend = 100
ldi
r16,73
;Kehrwert
von 7 *256 *2
ldi r17,dividend
mul
r16,r17
;Multiplizieren
lsr
r1
;Durch 2 teilen und r0 verwerfen
mov
r16,r1
;Ergebnis
retten
ldi
r18,7
;Quotient * 7
mul r18,r1
sub
r17,r0
;Divident
- (Quotient*7)
Das Ergebnis befindet sich am Ende in r16 und der Rest in r17. Wird der Rest benötigt und wir haben einen Tiny am Start, für welchen "mul" ein Fremdwort ist, sollte man überlegen ob nicht eine Division über Software Sinnvoll wäre, da eine solche Routine den Rest automatisch liefert.
Division
in Software
Leider gibt es bei den AVRs keinen Hardwaredividierer, jedoch ist es kein Problem in Software zu dividieren. Ähnlich wie in der Grundschule, holen wir von links die erste Ziffer aus dem Dividenden (im Binärsystem ja nur 0 oder 1)und schauen ob diese grösser oder gleich unserem Divisor ist. Ist der Divisor kleiner, tragen wir eine 0 in den Quotienten ein. Das müssen Grundschüler bei den ersten Ziffern zwar nicht, beim Binären dividieren steht jedoch die Anzahl der Bits im Quotienten fest. Nun holen wir die nächste Zahl "herunter", schieben also die nächste Ziffer dazu. Dieser Vorgang wird solange wiederholt, bis unser Divisor in die Ziffernfolge (Binärmuster) "geht". Jetzt tragen wir eine 1 in den Quotienten ein und Subtrahieren den Divisor von unserer Ziffernfolge. Danach geht es weiter wie gehabt. Bei einer 16/8 Bit Division, wie sie unten zu sehen ist, machen wir das 16 mal und die Division ist fertig.
#include
"m48def.inc"
.def temp1
= r16
.def temp2
= r17
.def temp3
= r18
.def temp4
= r19
.equ
dividend = 4711
ldi temp2,low(dividend)
ldi temp3,high(dividend)
rcall div
brk: rjmp
brk
;--------------------------------------------------------------------------------
; 16Bit Division durch 8Bit Konstante. In
diesem Fall 10.
;
Übergaberegister & Ergebniss in temp2/temp3 (low/high), Rest =
temp1
;--------------------------------------------------------------------------------
div:
ldi
temp4,16 ;16* schieben
clr
temp1 ;Rest
=0
dv1:
lsl
temp2 ;Ein
Bit aus dem Dividend
...
rol
temp3 ;ins
Carry schieben
rol
temp1
;Carry in den Rest schieben
;brcs
dv3
;Bei Überlauf von Rest, Sprung
cpi
temp1,10 ;Solange Bits in temp1 (Rest)
schieben bis
>= 10
brcs
dv2
;Wenn Rest <10,
das 0-Bit in temp2 (LSL, oben) stehen lassen
dv3:
inc
temp2
;Ansonsten Bit0 setzen und 10
vom Rest abziehen
subi temp1,10
dv2:
dec
temp4 ;Das
ganze 16 mal
brne dv1
ret
;-------------------------------------------------
;
Ende Div Routine.
;-------------------------------------------------
Im Code oben. wandern die Bits des Dividenden (temp2:temp3)
solange
in den Rest (temp1),
bis der Rest grösser oder gleich dem Divisor (10)
ist. Ist dies der Fall, wird Bit 0 im Quotient gesetzt. Der Quotient
braucht kein eigenes Register und landet auch in
temp1:temp2
welches am Anfang den Dividenden enthält. Dies ist möglich, da ja das
MSB durch linksschieben zuerst aus dem Dividenden geholt wird.Das LSB
ist zu diesem Zeitpunkt noch Null und wird erst nach dem Vergleich
durch inc
temp2 gesetzt, oder eben nicht.
Der Divisor in der Routine oben, darf in dieser Form max. 127
betragen und ist oben mit 10 definiert. Soll auch der Divisor variabel
sein,
ändert man einfach cpi
temp1,10 in cp
temp1,divisor und subi
temp1,10
in sub
temp1,divisor.
Ist der Divisor grösser als 127 (Bit 7 ist gesetzt), kann während
der Laufzeit der Rest bei rol temp1
überlaufen. Deshalb muss noch der
Befehl brcs
dv3 aktiviert werden. Dieser überspringt bei einem
Überlauf den
nachfolgenden Vergleich und setzt Bit 0 im Quotient. Keine Angst, die
Subtraktion von unserem 9 Bit Wert, stimmt (Im Simulator testen).
Ist genügend Flashspeicher vorhanden, könnte man noch die Laufzeit der
Routine verringern. Da wir wissen, das den Divisor 10 beträgt und die
Binäre 10 vierstellig ist, könnte man schon vor der Schleife ohne zu
vergleichen, 4 mal vom Dividenden in den Rest schieben und hätten dann
nur noch 12 Durchgänge in der Schleife.
Auch diese Routine lässt sich leicht an andere Bitbreiten
anpassen.
Unten ein Beispiel einer 32/16 Bit Divisionsroutine mit variablem
Divisor.
#include
"m48def.inc"
.def temp1
= r16
.def temp2
= r17
.def temp3
= r18
.def temp4
= r19
.def temp5
= r20
.equ
dividend = 0x12345678
.equ
divisor =
0xaffe
ldi
temp1,byte1(dividend) ;Testwerte laden
ldi temp2,byte2(dividend)
ldi temp3,byte3(dividend)
ldi temp4,byte4(dividend)
ldi yl,low(divisor)
ldi yh,high(divisor)
rcall
div
;Dividieren
brk: rjmp
brk
;Ende
;--------------------------------------------------------------------------------
; 32Bit Division durch 16Bit.
;
Übergaberegister & Ergebniss in Temp1-4 (low-high), Divisor = Y
Rest = Z
;--------------------------------------------------------------------------------
div:
ldi
temp5,32 ;32* schieben
clr
zl
;Rest =0
clr zh
dv1:
lsl
temp1 ;Ein
Bit aus dem Dividend
...
rol
temp2 ;ins
Carry schieben
rol temp3
rol temp4
rol
zl
;Carry in den
Rest schieben
rol zh
brcs
dv3
;Bei Überlauf von
Rest, Sprung
cp
zl,yl
;Solange Bits in temp1 (Rest)
schieben bis >= divisor
cpc zh,yh
brcs
dv2
;Bei
Rest<Divisor, die eingeschobene 0 in temp1 stehen lassen
dv3:
inc
temp1
;Ansonsten Bit0 setzen und
den Divisor vom Rest abziehen
sub zl,yl
sbc zh,yh
dv2:
dec
temp5 ;Das
ganze 32 mal
brne dv1
ret
;-------------------------------------------------
;
Ende Div Routine.
;-------------------------------------------------
Rechnen
mit Festkomma
Das ganze beruht darauf, dass man z.B. Euro auf dem Display
ausgibt,
aber mit Cent rechnet und ein Dezimalpunkt in die Ausgaberoutine
hineinschummelt.
Typisches Beispiel
Wir lesen mit dem AD-Wandler einen
Wert aus, den wir in Volt ausgeben möchten. Damit man das ohne Hardware
durchspielen kann, soll unser einfaches (theoretisches) Voltmeter
von 0 - 5 Volt mit 2 Nachkommastellen anzeigen. Der interne AD-Wandler
hat eine Auflösung von 10 Bit. Wenn wir vref auf 5 Volt
einstellen, können wir am ADC Eingang zwischen 0 und 5V messen, die der
ADC als Werte zwischen 0..1023 liefert. Das sind 1024 Werte in
Schritten von (5/1024 =) 0,0048828125 Volt. Der ADC-Wert muss also mit
0,0048828125 multipliziert werden um die momentane Spannung zu
berechnen. Da wir 2 Stellen hinter dem Komma anzeigen wollen wird
zuerst mit
100 multipliziert.
0,0048828125 * 100 = 0,48828125. Mit dieser Zahl, kann unser AVR noch
nichts anfangen,wir multiplizieren mit 256.
0,48828125 *
256 = 125. Prima, so glatt geht das selten aus. Wenn wir also jetzt den
ausgelesenen ADC-Wert mit 125 multiplizieren und im 24 Bit Produkt das
niederste Byte verwerfen, erhalten wir die Spannung*100 als 16 Bit
Zahl. Es muss bei
der Ausgabe nur noch ein Komma vor die beiden letzten Ziffern gesetzt
werden und wir erhalten eine Anzeige in Volt mit 2 Nachkommastellen.
Diese wollen wir noch runden. Wenn im Niederwertigsten (zu
verwerfenden) Byte, Bit 7
gesetzt ist soll Auf-, ansonsten Abgerundet werden. Das geht am
einfachsten wenn man zum Ergebnis 128 addiert.
Anschließend soll die Errechnete Spannung im SRam als String abgelegt
werden um ihn z.B. auf einem LCD auszugeben oder über die Serielle
Schnittstelle zu senden. Ganz oben im ersten Beispiel, wird gezeigt wie
eine 16Bit Zahl durch Divison von 1000,100,10 und 1 in einzelne Ziffern
zerlegt und so zur Ausgabe vorbereitet wird. In Beispiel unten, möchte
ich eine noch andere Möglichkeit Aufzeigen. Man kann den String auch
bilden, indem die Zahl immer wieder durch 10 dividiert wird und den
Rest von hinten her in den String schreibt. Beispiel: die Zahl ist 345.
345/10=34 Rest 5 (5 in den String). 34/10=3 Rest 4 (4 in den String)
.3/10 = 0 Rest 3. Die letzte Division könnte man also auch sparen, wenn
man den Dividend der letzten Division (3/10) in den String schreibt.
#include
"m48def.inc"
.def temp1
= r16
.def temp2
= r17
.def temp3
= r18
.def temp4
= r19
.def null
= r2
.equ adcwert = 1020
;Testwert
;--------------------------------------------------
;Stack, Ports, ADC usw.initialisieren
;--------------------------------------------------
init: nop
clr
null
;Wird zum addieren des Carryflags gebraucht
;--------------------------------------------------
;Hauptprogramm
;--------------------------------------------------
main: rcall
r_adc
;ADC Auslesen
rcall
calc
;In Volt umrechnen
rcall
string
;Zur Ausgabe vorbereiten
rjmp main
;--------------------------------------------------
;Dieser Teil soll die ADC-Ausleseroutine Simulieren
;--------------------------------------------------
r_adc: ldi
xl,low(adcwert) ;Testwert laden
ldi xh,high(adcwert)
ret
;--------------------------------------------------------------
;In Volt mit 2 Nakommastellen Umrechnen (mul Version)
;Dazu mit 125 multiplizieren, runden und letztes Byte verwerfen
;--------------------------------------------------------------
/*
calc: ldi
temp1,125
;Multiplikator laden
mul
xh,temp1
;Highbyte multiplizieren
movw
temp3:temp4,r0:r1 ;Um 1 Byte Verschoben (*256) ins
Produkt
mul
xl,temp1
;Lowbyte Multiplizieren
mov
temp2,r0
;Lowbyte direkt zum Produkt
add
temp3,r1
;Highbyte addieren
adc temp4,null
;------
;Runden
;------
ldi
temp1,128
;0b10000000 addieren um einen
add
temp2,temp1
;Übertrag
bei gesetztem Bit 7
adc
temp3,null
;zu
bewirken (aufrunden)
adc temp4,null
ret
*/
;-----------------------------------------------------------------
;In Volt mit 2 Nakommastellen Umrechnen (Schiebeversion)
;Dazu mit 125 multiplizieren, runden und letztes Byte verwerfen
;-----------------------------------------------------------------
calc: clr
temp2
movw
temp3:temp4,x
;temp2..4 enthält
jetzt den ADCWert *256
lsl xl
rol
xh
;ADC *2
add xl,temp3
adc
xh,temp4
;ADC *3
lsr
temp4
;*256 /2 = *128
ror temp3
ror temp2
sub
temp2,xl
;*128 - *3 = *125
sbc temp3,xh
sbci
temp4,0
;------
;Runden
;------
subi
temp2,128
;0b10000000 addieren um einen
sbci
temp3,-1
;Übertrag bei gesetztem Bit 7
sbci
temp4,-1
;zu bewirken (aufrunden)
ret
;--------------------------------------------------------------------
; Einen String aus der berechneten Zahl
bilden und im SRam ablegen
;--------------------------------------------------------------------
string: ldi
yl,low(sram_start+5) ;Endadresse des
Strings nach Y
ldi
yh,high(sram_start+5) ;String von hinten aufbauen
clr
temp1
;String mit 0 Abschliessen
st -y,temp1
rcall
div
;Ziffer für Hundertstel in den String
rcall
div
;Zehntel
ldi temp1,','
st
-y,temp1
;Komma
rcall
div
;Einer
ret
;------------------------------------------------------------------------
; 16Bit Division durch 8Bit Konstante. In
diesem Fall 10.
;
Übergaberegister & Ergebniss in temp3/temp4 (low/high), Rest =
temp2
;------------------------------------------------------------------------
div:
ldi
temp1,16 ;16* schieben
clr
temp2 ;Rest
=0
dv1:
lsl
temp3 ;Ein
Bit aus dem Dividend
...
rol
temp4 ;ins
Carry schieben
rol
temp2
;Carry in den Rest schieben
;
brcs
dv3
;Bei Überlauf von
Rest, Sprung
cpi
temp2,10 ;Solange Bits in temp1 (Rest)
schieben bis
>= 10
brcs
dv2
;Wenn der Rest
<10 ist, das 0-Bit in temp2 (LSL, oben) stehen lassen
dv3:
inc
temp3
;Ansonsten Bit0 setzen und 10
vom Rest abziehen
subi temp2,10
dv2:
dec
temp1 ;Das
ganze 16 mal
brne dv1
;-------------------------------------------------
;
Ende Div Routine.
;-------------------------------------------------
subi temp2,-'0' ;ASCii Code von
"0" zum Rest addieren
st
-y,temp2 ;ASCii Code
der Ziffer in den String
ret
Da es ja hier nur um die Berechnung gehen soll, wird der ADC
nur
Simuliert. Der Wert der berechnet werden soll, kann man oben bei adcwert
eintragen. Das Unterprogramm calc,
welches den ADC-Wert mit 125 multipliziert, ist 2 mal
aufgeführt.
Die Auskommentierte Variante nutzt mit dem mul Befehl den
Hardwaremultiplizierer. Die Schiebe Variante soll zeigen, das wir hier
auch ohne den mul
Befehl auskommen würden. Diese Variante braucht zwar ein paar Befehle
mehr, ist aber in 12 Zyklen durch und somit immer noch (Sau)schnell.
Auch beim runden (addieren der 128) sind 2 Varianten vorhanden. Die
herkömmliche Art, braucht einen Befehl mehr und das zusätzliche
Register Null,
welches natürlich auch mit 0 initialisiert sein muss, da
AVRs keine immediate
Additionsbefehle zulassen.
Wie schon oben erwähnt, wird hier der String von hinten aufgebaut.
Da wir wissen, das wir 3 Ziffern ein Komma und die Null zum abschließen
des Strings haben, wird zum Y Zeiger 5 addiert. Achtung, bei st
-y,temp1, wird vor
dem speichern von temp1
der Zeiger dekrementiert, sodass der String genau an sram_start
beginnt.
Die Divisionsroutine ist schon unter Dividieren in Software
beschrieben. Am Ende der Division wird die Ziffer vom Rest noch durch
addieren des ASCii Zeichen "0" in ASCii gewandelt und in den String
geschoben. Das könnte man bei grösseren Zahlen genau so fortführen.
Führende Nullen könnte man vermeiden, indem man vor dem Aufrufen von rcall div
den Dividend (temp2,
temp3) auf Null prüft und gegebenenfalls ein Leerzeichen
einfügt.

